沒了解過 Cache,就別說網站性能沒救了!

現今的網頁架構相較於過往偏向靜態的形式已經變得複雜許多,大部分資料都要靠動態抓取,而抓取資料的過程就會產生許多 Request 請求去取得 Response ,不管是 client 端對 API 的 Ajax 操作,或是 server 端對資料庫的 query 都是類似的形式,而抓取資料的過程是需要時間的:client call API 後要等待 API response、backend 下 DB query 後也要等待資料庫查詢結果回傳,而當這樣的請求ㄧ多,例如高並發的狀況,是很有可能對服務的性能造成影響的,為了解決這個困境,就需要本篇文章的主角隆重登場了,那就是快取 (Cache)。
什麼是快取?
首先讓我們先思考一下前言的問題,如果一直去發出網路請求或是 DB query 會造成性能影響的話,你想到最直覺的解決方式會是什麼?
那就不要發出網路請求或 DB query啊!
咦,講幹話嗎,怎麼聽起來跟「吃飯會花錢怎麼辦?那就不要吃飯啊!」一樣無理。不過看似無濟於事的一個方式,卻是快取的核心概念。快取的概念其實就是提供一個額外的儲存空間,將可能需要透過請求得到的資料放在裡面,當之後要再請求資料時,先別急著發出請求,先問問快取它有沒有你要的資料吧,有的話很好,那你資料直接跟快取拿就好,也就省略了真的發出 request 的步驟,取得資料的速度也理所當然會提升,如果快取沒有你要的資料,再發出 request 去取得。而通常適合被快取的資料有兩項特性:
- 很常被使用到
- 資料不常變動
快取的種類
其實快取一開始出現時是在指 OS 方面的機制,透過快取 ,CPU 可以不必一直到 main memory 去拿資料,從而減少性能的耗損,後來這個概念被運用到了 OS 層以外的地方,以下就來介紹常見的幾種非 OS 層的快取形式:
Client Cache
client cache 所指的是伺服器與瀏覽器之間的快取機制,假設今天你是一個電商平台的開發者,而你們的商品大概每過幾個月才會更換一次,而看過電商網站就知道,賣東西是需要圖片來吸引消費者的,也就是說你的網站被瀏覽時,得透過 HTTP request 去下載上百張圖片,問題在於每次瀏覽都得重新下載一次所有圖片,但剛剛也說了,這些圖片可能幾個月才會更換,重複下載相同內容是浪費效能的一件事,於是我們可以把圖片存在瀏覽器的快取中,這樣除了第一次瀏覽網站要下載外,之後就可以直接去快取拿了。
client cache 的設定方式是透過 HTTP response header 去帶參數,browser 接收到後就會做對應的快取處理,詳細一點的介紹我推薦可以看胡立大大的文章,寫的非常仔細與易懂。
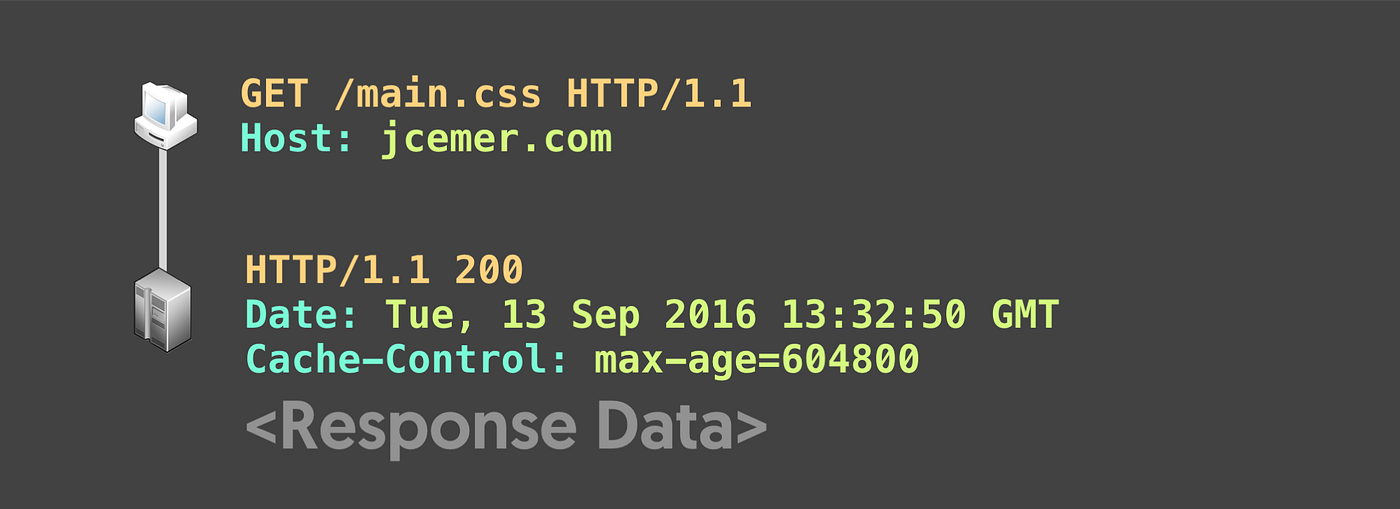
透過簡單的範例解釋一下快取流程,當 browser 第一次發送請求要取得 main.css 檔案時,server 在回傳的 response 帶入 Cache-Control 的資訊,並指定這個 cache 最大的生存時間為 604800 秒,browser 收到 response 後,將 main.css 放到瀏覽器快取中,之後在該 cache 生存時間內對於 main.css 的請求,就可以直接去 cache 取得檔案。

另一種方式是能透過 client 與 server 合作判斷檔案是否有受到更改,沒有更改的話可以直接取得快取的版本,關於 Last-Modified 與 If-Modified-Since 的介紹一樣建議看胡立大的文章,這邊就不細講了。
Networking Cache
要知道距離不僅僅是愛情的毒藥(誤),也是影響 response time 的重大因素。
假設你身在台灣,跟一個架設在台灣的 server 取資料,花費的時間只要 500 ms,但如果去跟一個架設在美國的 server 取相同的資料,這時候的 response time 可能就增長為 3000 ms。
而 Networking cache 的概念即是我們常常聽到的 CDN (Content Delivery Network)。
為了避免取資源時都要跟距離遙遠的 server 溝通,造成效能的耗損,這邊也可以運用到快取的概念來優化它,既然跟距離遙遠的 server 溝通效能會比較低,那就盡量避免這件事的發生。於是我們可以在離 request 方近一點的地方建立 CDN,儘管第一次發送 request 仍要跟位於美國的 server 溝通,但拿到資料後就可以存放在比較接近我們的 CDN 快取中,未來要取資料,若快取還沒到期,就直接到 CDN 去取就可以了。

關於 networking cache ,我建議可以參考這篇文章,話說馬克大的系列文真的太精彩了,只能推爆。
Application Cache
這邊也可以看成是 server side 的快取,快取存在的位置在 backend server 與 database 之間。在 web 2.0 以後,網頁內容大多是動態產生,因此資料庫的 I/O 操作也變得頻繁,I/O 的壓力也變成一個需要仔細注意的問題。採用 server side cache 在特定狀況下是可以解決這個問題的,其概念跟其他 cache 是一樣的,只是對象改為資料庫。當後端 server 要對其他伺服器發 request 取資料或是去資料庫取資料時,若是快取有資料且還沒到期就直接拿,沒有資料才做原本的 request 行為。知名的 Redis 就常被拿來當做 server side 的快取,以分擔資料庫的 I/O 壓力。
Why Redis ?
redis 本身是一個 open source 的 in memory的 key-value資料庫,他的優點在於效能超高,並且資料結構簡單,但也因為他的 in memory 特性,所以若是 redis 掛掉的話就會有 data loss 的問題產生,所以適合用在資料掉了也沒關係的場景,也就是 cache data。
Redis 的使用場景
- 配合 RDBMS 做高速快取
- 高頻次,熱門訪問的數據,降低資料庫 I/O
- 分散式架構,做 session共享
- 利用多樣的數據結構儲存特定的數據

總結一下使用 Redis 作為 cache 的優點
- 與查詢資料庫之類的網絡服務相比,訪問 local cache 所需的時間要小幾個數量級。
- 極大地減少應用程序獲取數據的延遲,並同時減少資料庫端的負載。
- 資料庫系統接收的查詢較少,從而可以使用更少的節點來提供相同的數據集。
當然 Redis 也是擁有缺點的,例如其中一個是 cache miss 的問題,其實 cache miss 可以再細分成三種狀況,並且也有對應的解法,但因為超出本篇的範圍於是請讀者自行研究囉。
關於 redis 最最最簡單的應用,可以參考下圖

上圖是一開始學習 cache 時寫的範例,當 call 我們自己的 endpoint 時,會去第三方服務抓取寶可夢的資料,cache 的應用方式則像之前提過的,先去看看 redis cache 有沒有資料,可以適時避免多餘的 request。
另外 Redis 的應用很廣泛,也可以拿來做 rate limiter(使用 expire 特性,計算一定時間內特定 ip 的 request 數量),有興趣可以參考下面的 repo
不過這個 repo 真的只是示範性質,當時因為剛學後端,幾乎沒考慮到什麼更細部的問題(效能、架構、DB 連線與 CAP 理論),所以看看知道 redis 還能做 rate limiter 就好 XD。
小結
這篇文章簡單說明了快取的概念,我們可以發現它其實是一個既通用又抽象的概念,在許多需要減少耗能行為的狀況下就有快取存在的價值,不管是 OS 層、client side、server side、networking 都有不同實作的方式,所以用得好的話是可以在許多層面提升服務的效能跟減少消耗性能的操作次數的,不過前提是要「用的好」,若是濫用,最終大部分請求還是要真的去跟 data source 抓取,這樣反而多了要去訪問快取的時間,效能就會不升反降了喔!
