初步認識分散式資料庫與 NoSQL CAP 理論

(以下圖片來源出自讀書會成員講義)
在談分散式以前,首先來談談單機運作的概念。當我們的服務是單機運作時,伺服器的架構設計通常會是以下其中一種:
- 一個服務在一台電腦運行
- 多個服務在一台電腦運行
這種狀況下若是要擴展系統容量,只能升級電腦資源獲提升程式效率,這種方式也被稱為「垂直擴展(Vertical Scaling)」。
不過這樣的架構又衍生出兩個問題:
- 單機能力的提升是有極限的
- 單點故障的風險(Single Point of Failure): 若只依靠單機運行,假設今天資料庫的主機掛了,你的服務也就 GG 了。換句話說就是缺少容錯能力,無法在維持服務的前提下升級。
為了解決以上的問題,有個解法誕生了:
嘗試開很多個機器跑同一個服務,也就是採用分散式架構
在開了很多台機器後,我們似乎得到以下的好處:
- 來自 client 的請求可以分配到這幾台主機之一,減緩單一主機的壓力。
- 因為第一點,某種程度降低了服務的等待時間。
- 提高了系統的容錯能力,即是一個分區容錯(Partition Tolerence)的系統,當節點間通訊失敗也不會影響系統正常運作。
- 採用分散式架構後,甚至可以在不同地理區域就近服務使用者。
這種增加節點的擴容方式,被稱作水平擴展(Horizontal Scaling)
然而,事情不像外表看起來那麼單純又美好,進入分散式世界後所需要考慮的事情變得更多更複雜了。
在上一篇文章中我們提及 transaction 可以解決資料一致性的問題,然而在分散式架構下我們無法僅靠 transaction 就確保一致性,必須額外搭配共識(Consensus)的機制。

接下來介紹幾個名詞:
- Consistency 一致性 : 保證在各個有儲存資料的分區都一定拿得到最新版本的資料。
- Availability 可用性:當存取資料庫時一定可以拿到資料,不會出錯(不會出現拿不到資料的狀況,但拿到的資料不保證是最新版本。)
- Partitioning Tolerance 分區容忍:文章前段有提及,即使任一節點發生錯誤,整個系統還是能正常運作。
問題來了,有辦法同時達到 C (一致性),、A (可用性)、P (分區容忍) 嗎?
答案是沒辦法。讓我們來看看 CAP 理論是什麼。
CAP 理論

所謂 CAP 理論以中文有名的諺語來說就是「魚與熊掌不可兼得」在分散式系統中不可能同時滿足 CAP 三者。CAP (C (一致性),、A (可用性)、P (分區容忍))三者只能擇其二(或是勉強都達到一點點點),也就是選擇了 P,就只能再從 C, A 中二選一,如果 CA 都要拿,那就都會無法做到完美。
幾種 CAP 的組合
AP Database — 犧牲一致性的分散式資料庫
在分區容忍的前提下(因為都已經採用分散式架構了),犧牲一致性來提高可用性(盡可能每次都得到回應),不過雖然犧牲了一致性,卻仍可以達到最終一致性(Eventual Consistency,例如總統大選開票時每家新聞台的即時票數都不一致,但在選舉結束後的票數還是會達成一致。),適合在需要快速讀寫,但資料對於一致性的需求較低的場景,例如臉書或各大媒體平台的按讚系統。
例如:Amazon DynamoDB
CP Database — 犧牲可用性的分散式資料庫
在分區容忍的前提下,依然可以得到最新版本的資料,常用於貼文系統、訊息系統等不能犧牲一致性的系統。
例如:Google BigTable、MongoDB、分散式的 RDBMS
CA Database — 犧牲分區容忍性的資料庫
這樣就違反了分散式架構的初衷,因此基本上不會存在於分散式系統中。
例如:單機或是經過 Sharding 的資料庫(不能承受單機損壞)。
Scaling & Availability
接著來提一下擴展與可用性。
Q: RDBMS 怎麼做 Scaling ?
A: Database Sharding。

不過實作過程可說是非常複雜。
Q: 那 RDBMS 怎麼做到高可用性呢?(HA, high availability)
A:
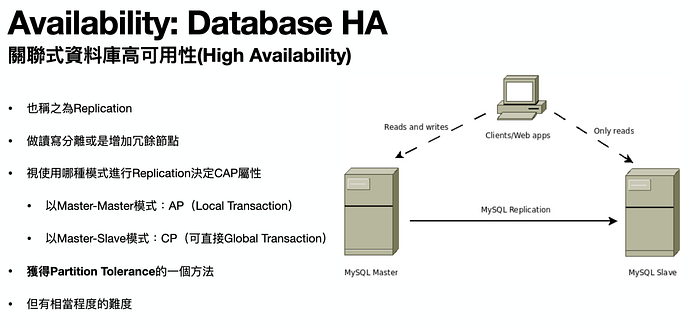
看完 RDBMS,換來看看 NoSQL 的優缺點。
NoSQL 解決了什麼問題?
- 容易擴展的設計架構,由於資料沒有關聯性,因此相較於 RDBMS 更易於 scaling。
- 簡單快速的達到高可用性(HA): Hash Function: O(1), Distributed Hash Funciton: O(log n)
- 容易進行 Schema 的變更,因為根本沒有 Schema,適合時常變更架構的系統。
然而,老樣子,沒有絕對完美的事情,NoSQL 一樣存在缺點。
NoSQL 的缺點
- 沒有固定的 Schema : 這點其實嚴格來說可以是優點也可以是缺點,得看需求來定論。
- 關聯式資料庫常見的 Transaction 與 JOIN 也就非常難在 NoSQL 實踐。
- 資料量不夠大時,其實效能普遍比 RDBMS 來要差
這邊提到了 Transaction,剛好在之前的篇章也淺淺介紹過 transaction,不過當時只考慮到單機運行的狀況,那在分散式的架構下的 Transaction 又會有什麼不一樣呢?文章開頭有提到,我們需要共識機制的幫忙。
其實共識機制有非常非常多種,不過在分散式資料庫中最常見的共識機制就是 2PC 這個共識機制。

分散式關聯性資料庫的範例:

關於分散式交易的更多資訊

小結
透過這篇文章,我們大概了解了單機與分散式的架構差異,還有一致性、可用性、分區容忍性魚與熊掌不可兼得的 CAP 理論,也理解到不同組合的資料庫種類,還有分散式架構需要共識機制來完成交易,最後也稍微提到 RDBMS 與 NoSQL 非別怎麼擴展與兩者的區別。不過這篇真的是超淺淺淺談,現實面還有很多需要考慮的問題,分散式也未必是大流量需求下最佳的選擇,因此想要使用時還要謹慎看待囉!
